|
|
|
|
|
|
|
|
|
|
|
|
|
|||
 |
||
|
|
|
|
Abstract
Generated Audio Demo
|
|  |
Videos
| ISBI 2020 Talk |
Paper and Supplementary Material
 |
Wang, Ran and Chen, Xupeng and Khalilian-Gourtani, Amirhossein and Chen, Zhaoxi and Yu, Leyao and Flinker, Adeen and Wang, Yao. Stimulus Speech Decoding From Human Cortex With Generative Adversarial Network Transfer Learning. In ISBI, 2020. (hosted here) |
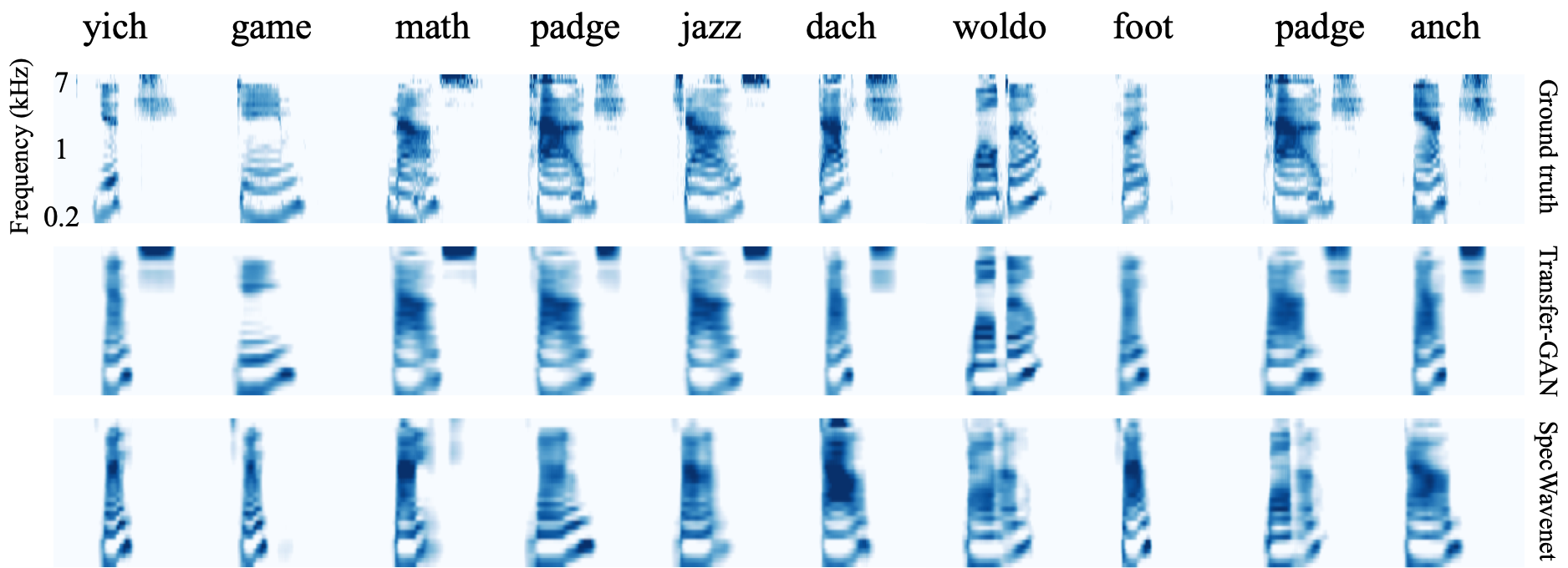
Performance comparisons
 |
|
|
Quantitative comparison of transfer-GAN (proposed), SpecWaveNet, and linear model in MSE (lower is better) and CC (higher is better) on test data. “-” refers to number not reported.
Model Architecture
 |
|
|
 |
|
|
Averaged evolution of the attention mask
 |
|
|